¿Cómo empezar en Data Science?
Guía recomendada para aquellos interesados en el campo de Data Science y no saben por dónde empezar.

- 1. Introducción
- 2. Matemáticas
- 3. Fundamentos del Machine Learning
- 4. Lenguajes de Programación
- 5. Apuntes finales
- 6. Recursos adicionales
1. Introducción
Cuando uno se aventura a introducirse en el mundo de la ciencia de datos, el machine learning y la ola de la revolución 4.0; se encuentra en un mar de decisiones y no sabe realmente por dónde empezar. Algunos recomiendan bootcamps, otros lanzarse directamente a programar.
Aunque todas las opciones son válidas, lo cierto es que este primer paso puede ser abrumador, incluso si ya se viene con cierta preparación previa. Es por eso que he decidido recopilar aquellos conceptos que considero importantes y que me han servido para entender mejor lo que subyace a estas tecnologías, para explotarlas en nuestro beneficio.
2. Matemáticas
Nadie dijo que el camino fuese a ser sencillo. Para poder convertirse en un buen científico de datos, es necesario tener cierta soltura en las operaciones matemáticas que vamos a utilizar.

Las matemáticas nos ayudan a:
- extraer conclusiones a partir de los datos
- forman el principio fundamental detrás de cualquier modelo de ML que quieras utilizar
- nos permitirá ajustar los modelos a los requerimientos del problema (hyperparameters tuning, funciones de pérdida)
- escoger el modelo apropiado y qué métricas de evaluación son más adecuadas
En definitiva, nos ayudan a escoger EL modelo que el problema necesita, y sobretodo, hacerlo con fundamento, algo crucial cuando haya que defender tu decisión frente a un equipo, clientes o stakeholders.
2.1. Álgebra lineal
El álgebra lineal recoje el área de conocimiento de las matemáticas relacionada con los vectores, las matrices y las transformaciones lineales; fundamentales para la representación, almacenamiento y eficiencia de los datos.
2.2. Estadística
Nos permite cuantificar cómo de probable es que una serie de eventos vayan o no a suceder.
Conceptos como medias muestrales, medianas, varianza, cuartiles y desviación estándar son esenciales para realizar el análisis exploratorio de los datos y su tendencia. Así como para evaluar correctamente los modelos y poder elegir de entre varios candidatos, qué modelo obtiene los mejores resultados.
2.3. Cálculo
El cálculo es la piedra fundamental sobre la que se sustenta el Machine Learning, sin él, no existirían los algoritmos de optimización como el descenso por gradiente. Los modelos se encontrarían literalmente ciegos en el espacio y no tendrían manera de determinar hacia qué dirección (pesos) debería de dirigirse a continuación para minimizar el error.
Debemos ser conscientes y habilidosos en el cálculo diferencial y su intuición lógica, para poder entender cómo funcionan las redes neuronales.
3. Fundamentos del Machine Learning
En esencia, Machine Learning es coger todos los conceptos matemáticos previos y aplicarlos.
Por eso es importante tener una base sólida previa en matemáticas, para poder entender el funcionamiento interno del aprendizaje automático. Estos fundamentos son importantes para poder construir modelos de ML robustos.
Podríamos dividir los algoritmos de ML en dos grandes bloques: aprendizaje supervisado y no supervisado.
Aunque esta clasificación nos dice únicamente el método utilizado para que los modelos aprendan.
En el aprendizaje supervisado quiere decir que el problema trata de un escenario donde tenemos las respuestas de antemano.
Pongamos el ejemplo en el que tengo una serie de fotografías de números escritos a mano junto con sus etiquetas correspondientes, que indican qué número representa cada fotografía. El modelo utilizará estas imágenes etiquetadas para aprender a identificar patrones que diferencian un número de otro.
El objetivo del modelo será asociar unos inputs a una salida esperada, y conseguir predecir la variable objetivo con nuevas entradas; reduciendo el error cometido.
Por otro lado, en el aprendizaje no supervisado, tenemos una serie de datos de los que no tenemos una variable objetivo sobre la que obtener un valor, sino que en su lugar nos permite descubrir patrones y tendencias dentro de los propios datos, sin tener claro de antemano qué estamos buscando.
Este concepto es menos intuitivo, pero pongamos que dirigimos una tienda de música, y tenemos datos de los clientes sobre discos comprados, encuestas, valoraciones, pero también datos como la edad, sexo, o si están casados o con hijos. Imaginemos ahora que nos gustaría clasificarlos en grupos para dirigir campañas de marketing sobre un grupo concreto para mejorar el impacto de la publicación. Pues con este tipo de modelos, únicamente deberíamos de indicarle los datos de entrada y él mismo se encargaría de hacer la división –a este tipo de problema se le llama clustering (agrupamiento)–.
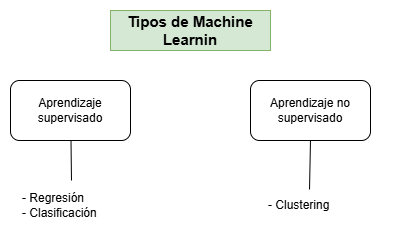
Los algoritmos de ML se categorizan de manera más general en: clasificación, regresión y clustering.
Los pasos para aplicar correctamente estos modelos son:
- Ingeniería de características y preprocesado de datos
- Entrenar el modelo y optimizar los hiperparámetros
- Evalúar el modelo
4. Lenguajes de Programación
Ser habilidoso en lenguajes de programación como Python o R es indispensable para poder llevar a cabo proyectos de Data Science. Estas son las herramientas que utilizaremos para llevar a cabo nuestros análisis y sacar los insights de los datos.
Mediante Python, podremos realizar todo el flujo de un proyecto típico de data science: desde la importación y limpieza de los datos, hasta la visualización y productivización del proyecto. Algunas librerías que deberemos de conocer son:
- Numpy para operaciones matriciales y álgebra lineal
- Pandas para la importación y nos proporciona el tipo de dato
dataframeque hace que trabajar con los datos sea mucho más cómodo - Matplotlib para visualizaciones
- Scikit-learn para modelos de machine learning y algoritmos típicos de normalización, entre otros
Para avanzar en este mundillo, también tendremos que tener en consideración aprender conceptos básicos como estructuras de datos (arrays, listas, diccionarios), clases y objetos; además de ser capaz de realizar análisis de complejidad espacial y temporal para desarrollar algoritmos que sean eficientes.
Por otro lado, la mayor parte de la información en las empresas, se encuentra en bases de datos relacionales, por tanto, también necesitaremos aprender SQL para nuestros proyectos, no necesitamos ser unos completos expertos, nuestro objetivo es utilizarlo de manera fluida, no competir con un administrador de bases de datos. Debemos de ser capaces de extraer, analizar y organizar la información en las primeras fases.
5. Apuntes finales
Aunque esta entrada se lea de manera lineal, no significa que para poder aprender programación tengas que pasar todas las fases anteriores, aunque sí es recomendable poder contar con una base sólida en algunos conceptos antes de meterte de cabeza en puntos más complejos, ya que como explicaba, el hecho de seguir esta metodología te permitirá aprender nuevos conceptos consolidando los que ya has obtenido en pasos anteriores.
Sin embargo, también considero que un enfoque puramente teórico en las primeras fases puede ser abrumador e incluso alejar a aquellos que quieran inciarse en este mundo.
Por tanto, en entradas posteriores daré algunas pinceladas de cómo poder introducirse a campos como las matemáticas o la estadística, utilizando herramientas como Python y R.
De esta manera, conseguirás aprender los conceptos teóricos a la vez que los pones en práctica en ejercicios y casos de uso prácticos, lo que creo mejorará tu experiencia de aprendizaje.
Sobretodo, tener en cuenta que este camino es un proceso que puede alargarse todo lo que quieras, y que realmente nunca termina, por tanto, disfruta del camino.
6. Recursos adicionales
Si quieres ampliar contenido, te recomiendo que sigas los siguientes canales enfocados a la ciencia de datos que te ayudarán a adentrarte en este mundo:
- La revista de Towards Data Science con artículos de actualidad muy interesantes.
- El canal de Data Science For Business tiene un enfoque muy práctico e incluso un curso de iniciación gratuito que te pondrá en la piel de un Data Scientist Jr.
- Kaggle contiene multitud de datasets con los que puedes practicar, o si te ves preparado, puedes participar en alguno de sus torneos.
- En Coursera encontrarás cursos enfocados a la ciencia de datos, entre otros muchos campos, de la mano de las mejores universidades del mundo. Lo bueno es que la mayoría de cursos son gratuitos y sólo tendrás que pagar si quieres recibir un certificado de finalización.